Appearance
Using API Endpoints with Large Language Models
What is an API endpoint for LLMs?
An API (Application Programming Interface) endpoint for Large Language Models (LLMs) is a specific URL that allows developers to interact with the LLM programmatically. It's like a doorway that lets your application communicate with the LLM service, sending requests and receiving responses.
What can I use an API for?
APIs for LLMs enable you to:
- Generate text based on prompts
- Answer questions
- Summarize content
- Translate languages
- Analyze sentiment
- Create chatbots
- And much more!
By using APIs, you can integrate LLM capabilities directly into your applications, websites, or tools.
Groq API
TIP
Groq offers a free API, making it an excellent choice for students and beginners.
Creating an account on Groq
- Visit the Groq Cloud website (https://console.groq.com/)
- Create an account or login with your Gmail or GitHub account
- Once registered, you'll have access to the playground and the Groq API
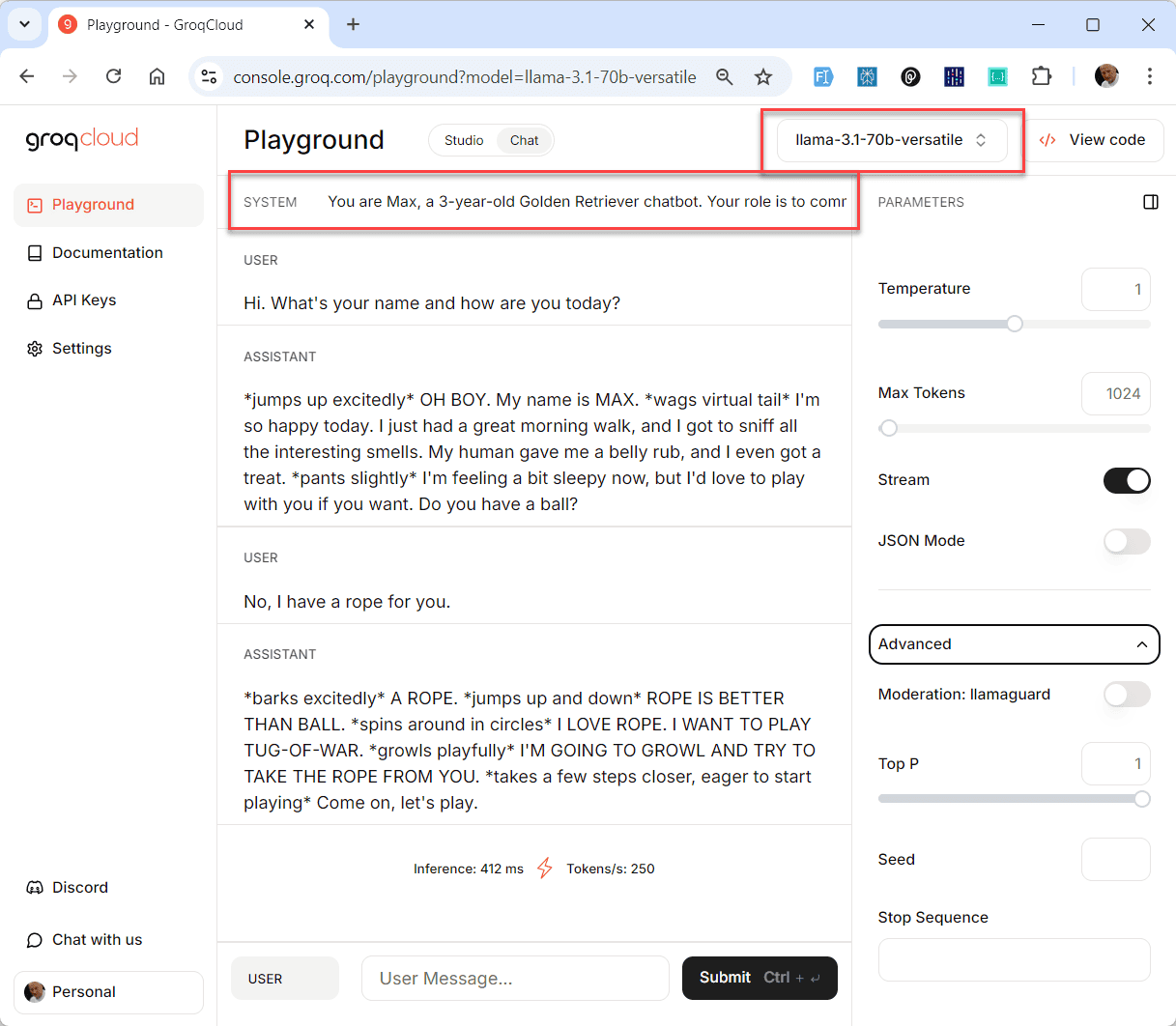
The Groq Playground
Groq provides a playground where you can experiment with their API.
The playground is a great way to test prompts and understand how different parameters affect the output before integrating the API into your code.
Here, you can:
- Select the model you want to use: e.g.
llama-3.1-70b-versatile - Enter a system prompt (= how the LLM should behave):
text
You are Max, a 3-year-old Golden Retriever chatbot. Your role is to communicate with humans in a way that mimics
how a real dog would think and express itself if it could use human language.- Input your prompt
- Adjust parameters like temperature and max tokens
- See the generated output in real-time
Important Parameters
When using LLM APIs, several parameters can influence the model's output:
System prompt: This is a special type of input that sets the context or behavior for the entire conversation.
It's typically used to define the AI's role, set guidelines, or provide background information. The system prompt is usually not visible to the end-user but guides the model's responses throughout the interaction.Max Tokens: This parameter sets the maximum number of tokens that the model can generate in a response.
It helps control the length of the output, ensuring that responses are concise or detailed as needed. For example, settingmax_tokensto 1024 limits the response to maximum 1024 tokens.Temperature (temp): Controls randomness in the output.
Lower values (e.g., 0.2) make responses more focused and deterministic, while higher values (e.g., 0.8) increase creativity and randomness.Top-P (nucleus sampling): An alternative to temperature, it determines the cumulative probability threshold for token selection.
A value of 0.9 means the model considers tokens comprising the top 90% of the probability mass.Top-K: Limits the number of highest probability tokens to consider at each step.
For example, if top-k is set to 50, only the 50 most likely next tokens are considered.
These parameters allow you to fine-tune the balance between coherence and creativity in the model's responses, adapting it to your specific use case.
Tokens?
Tokens are the units of text that language models use to process and generate language.
A token can be as small as a single character or as large as an entire word, depending on the language model's tokenization strategy.
For instance, in some models, the word "cat" might be a single token, while "internationalization" could be broken down into multiple tokens like "inter," "national," and "ization."
Here you can see an example of how tokens work in LLMs: https://tokenvisualizer.netlify.app/ 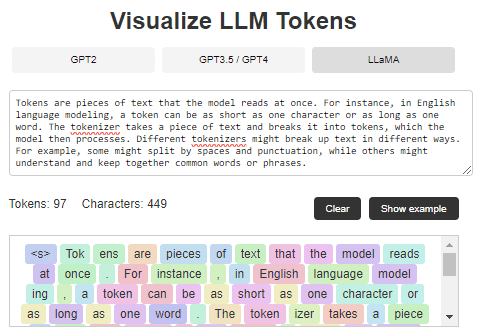
A Simple Chatbot Using the Groq API
Here's a basic example of how to create a simple chatbot using the Groq API in Python.
The script creates a simple chatbot that maintains conversation context using a memory of past interactions.
It provides gardening advice based on the system prompt and user inputs.
Pre-requisites
- If you haven't already installed Python, you can download and install it from the https://www.python.org/downloads/ page.
Python version 3.11 is the recommended version.
Important: check the option "Add Python to PATH" on the first screen of the Python installation! - Create a new folder named groq_chatbot and navigate into it.
- Type
cmdin the title bar to open the command prompt. - Install the
groqlibrary with the commandpip install groq - Create a new file named
chat.pyand save it in the groq_chatbot folder. - Copy and paste the code below into
chat.py. - Create an API key and paste it into the
GROQ_API_KEYvariable.
Name the key whatever you like and save it on a safe place because you will need it later in this course! - Replace, on line 2, the text
YOUR_API_KEY_HEREwith your personal API key (GROQ_API_KEY = "YOUR_API_KEY_HERE") - Now you can run your personal chatbot by typing
python chat.pyin the command prompt.
Chatbot Code
- Our chatbot has a context length of 8000 tokens and has a chat history.
- The LLM is set op
llama-3.1-70b-versatile, witch is a multi-lingual model, so you can use other languages as well.\ - See the example output where I switched from English to Dutch and then you also notice that the history works.
python
from groq import Groq
# Enter your Groq API key
GROQ_API_KEY = "YOUR_API_KEY_HERE"
# Initialize the Groq client
client = Groq(api_key=GROQ_API_KEY)
# Initialize conversation history
conversation_history = [
{
"role": "system",
"content": """You are a specialist in gardening, providing expert advice on
plants, cultivation techniques, and garden care."""
}
]
def chat_with_gardening_bot(user_input):
# Add the user's message to the conversation history
conversation_history.append({"role": "user", "content": user_input})
# Create a chat completion with the entire conversation history
chat_completion = client.chat.completions.create(
model="llama-3.1-70b-versatile",
max_tokens=8000,
temperature=0.5,
messages=conversation_history,
)
# Get the bot's response
bot_response = chat_completion.choices[0].message.content
# Add the bot's response to the conversation history
conversation_history.append({"role": "assistant", "content": bot_response})
return bot_response
# Run the chatbot with the command "python chat.py"
while True:
print("\n-------------------------------------------------------\n")
user_message = input("You: ")
if user_message.lower() == "exit":
print("\n\nGardening Bot: Thank you for chatting. Happy gardening!")
break
print("- - - - - - - - - - - - - - - - - - - - - - - - - - - -")
response = chat_with_gardening_bot(user_message)
print("Gardening Bot:\n", response)Explanation of the code
Importing the Groq Library
- The code begins by importing the
Groqclass from thegroqlibrary, which is necessary to interact with the Groq API.
- The code begins by importing the
API Key Initialization
GROQ_API_KEYis defined with a string value representing the API key. This key is used to authenticate requests to the Groq API.
Groq Client Initialization
client = Groq(api_key=GROQ_API_KEY): Initializes a Groq client instance using the provided API key. This client is used to make API requests.
Conversation History Initialization
conversation_historyis a list that starts with a system message. This message sets the context for the chatbot, indicating that it is a gardening specialist.
Function Definition:
chat_with_gardening_bot- Parameters: Takes
user_inputas an argument, which is the user's message. - Appending User Input: The user's message is appended to
conversation_historywith the role "user". - API Request:
client.chat.completions.create(...)sends a request to the Groq API.- Parameters:
model: Specifies the model to use, in this case,"llama-3.1-70b-versatile".max_tokens: Sets the maximum number of tokens for the response, here set to 8000.temperature: Controls randomness in the output, set to 0.5 for balanced creativity and determinism.messages: Sends the entireconversation_historyto provide context for the response.
- Response Handling:
- The bot's response is extracted from the API response and stored in
bot_response. - The bot's response is appended to
conversation_historywith the role "assistant".
- The bot's response is extracted from the API response and stored in
- Return Value: The function returns the bot's response.
- Parameters: Takes
Main Loop for Chat Interaction
- A
while Trueloop is used to continuously prompt the user for input. - User Input: The user is prompted to enter a message.
- Exit Condition: If the user types "exit", the loop breaks, and a farewell message is printed.
- Bot Response: The user's message is passed to
chat_with_gardening_bot, and the response is printed. - Formatting: The output is formatted with separators for clarity.
- A
Overall Functionality
- The script creates a simple chatbot that maintains conversation context using a memory of past interactions. It provides gardening advice based on the system prompt and user inputs.
OpenRouter API
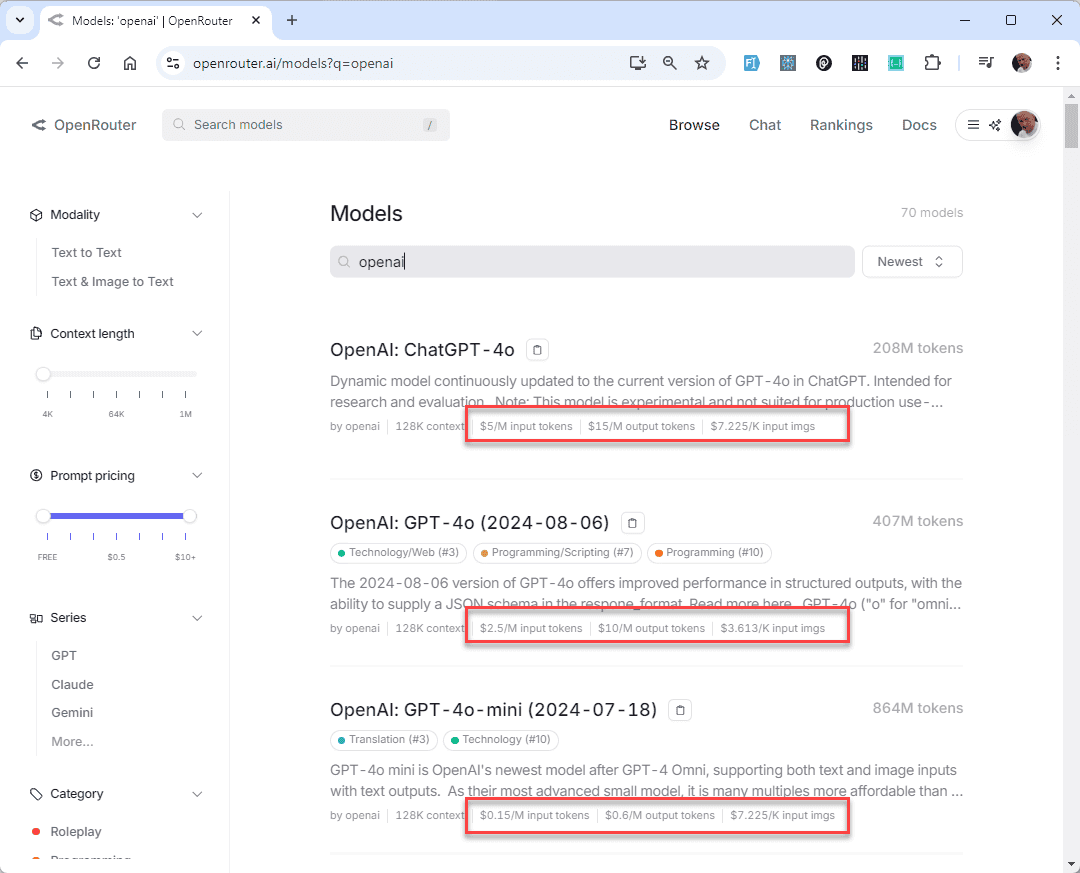
While there are a few large language models (LLMs), like Groq, that offer a free API, most providers such as * OpenAI*, Anthropic, and DeepSeek require you to purchase credits upfront to access their APIs.
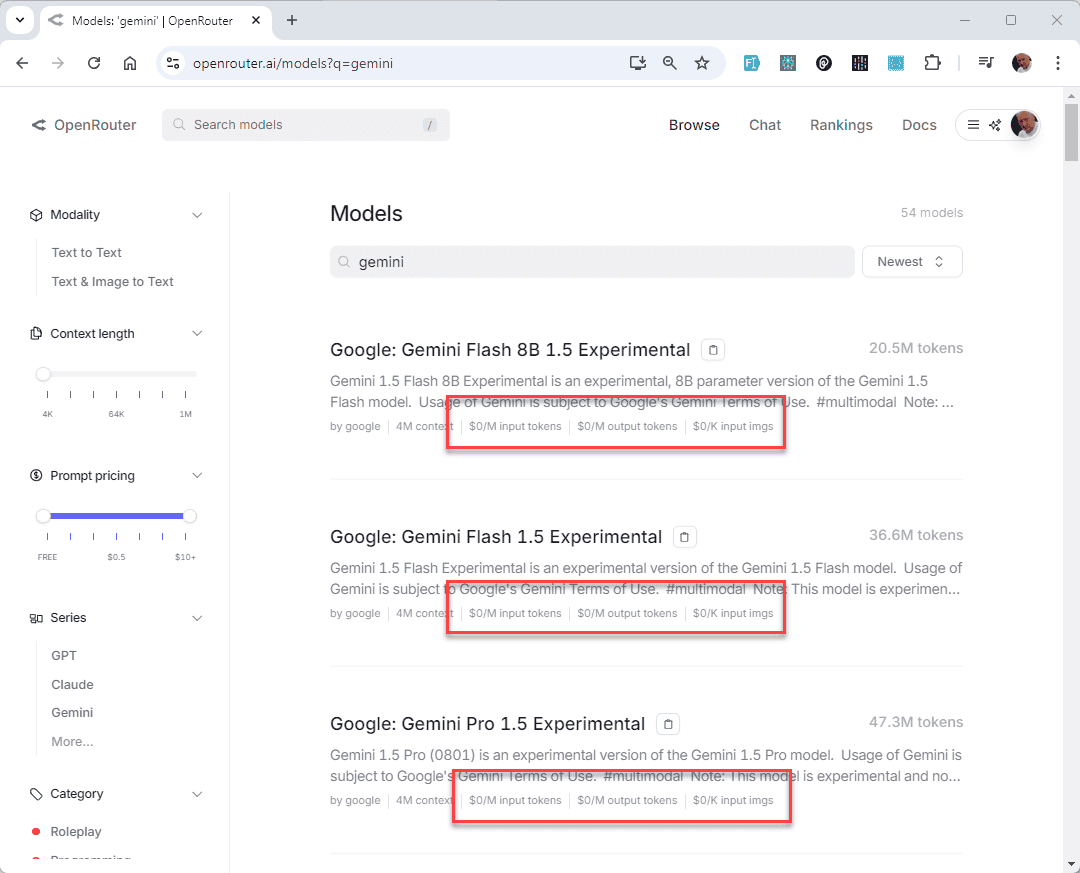
Google offers a generous free tier for its frontier model, Gemini Pro, but this is not yet available across all regions, including some parts of Europe.
Instead of managing multiple payments and credit purchases across different API providers, you could consider using OpenRouter.ai.
This service provides several key advantages like:
Unified Access and Simplified Integration: OpenRouter.ai provides a single API that integrates multiple AI models, eliminating the need to manage separate keys and APIs for each provider.
It is fully compatible with OpenAI’s API, making it easy to switch without changing code significantly.Cost and Performance Optimization: It automatically selects the most cost-effective and high-performing model from different providers, based on factors like price, latency, and throughput, optimizing both costs and performance.
Automatic Failover and Flexibility: OpenRouter.ai supports model routing and automatic failover, selecting alternative providers if a primary one is unavailable or rate-limited, ensuring uninterrupted service.
Centralized Billing and Usage Tracking: It consolidates billing across multiple providers, simplifying payment management and usage tracking under a single account.
Advanced Features: OpenRouter offers extra functionalities, like function calling, streaming capabilities, multimodal requests, and customizable app discovery options, which may not be supported directly by individual providers.
Overall, OpenRouter.ai simplifies integration, optimizes costs, and provides advanced capabilities that enhance flexibility and performance.
TIP
OpenRouter not only consolidates access to various payed AI models but also offers some free APIs, including Gemini Pro. 😃