Appearance
Large Language Models (LLMs)
Introduction
Exploring LLMs
Large Language Models (LLMs) are advanced artificial intelligence systems designed to understand, generate, and manipulate human-like text. These models are trained on vast amounts of textual data, allowing them to capture complex patterns in language and perform a wide range of natural language processing tasks.
Key characteristics of LLMs include:
Scale: LLMs are typically trained on billions of parameters, allowing them to capture intricate linguistic patterns.
Versatility: They can perform various tasks such as text generation, translation, summarization, and question-answering without task-specific training.
Context understanding: LLMs can comprehend and maintain context over long sequences of text.
Transfer learning: Knowledge acquired from pre-training can be applied to new, unseen tasks.
LLMs have revolutionized natural language processing and have found applications in diverse fields, from content creation to scientific research.
Classification of LLMs
LLMs can be classified based on various factors, including model size, capabilities, and intended use. Here's an updated classification reflecting the most recent models as of August 2024:
Frontier Models
- Examples: GPT-4o, Claude 3.5 Sonnet, Grok-2, Gemini 1.5 Pro and FlashMixtral Large 2, DeepSeek V2
- Characteristics:
- Massive scale (hundreds of billions of parameters or undisclosed)
- State-of-the-art performance across a wide range of tasks
- Often multimodal (text, image, video, voice)
- Typically proprietary with API access
Large Open-Source Models
- Examples: Llama 3.1 (405B), Mixtral 8x22B (141B),
- DBRX (132B), Nemotron-4 (340B)
- Characteristics:
- Tens to hundreds of billions of parameters
- Open-source, allowing for research and customization
- Strong performance on many tasks
- Suitable for fine-tuning and deployment
Medium-sized Models
- Examples: Jamba (52B), Command R (35B)
- Characteristics:
- Tens of billions of parameters
- Balance between performance and computational requirements
- Often available in both open-source and API formats
Efficient Small Models
- Examples: Mistral 7B (7.3B), Gemma (2B, 7B), Phi-3 (3.8B)
- Characteristics:
Specialized Models
- Examples: Sora (for video generation), domain-specific variants of larger models
- Characteristics:
- Focused on specific tasks or domains (e.g., code generation, video creation)
- May have custom architectures or training approaches
- Often integrated into larger AI ecosystems or products
This classification reflects the rapid evolution of LLMs, with a trend towards:
- Increasing model sizes for frontier models
- Improved efficiency in smaller models
- Greater availability of open-source options
- Specialization for specific tasks or industries
It's important to note that the field of LLMs is rapidly evolving, with new models and breakthroughs emerging frequently.
The capabilities and relative performance of these models can change quickly, and users should refer to the most recent benchmarks and evaluations when choosing a model for a specific application.
Understanding Parameters
Parameters in LLMs refer to the adjustable values that the model learns during training. These are essentially the " knowledge" of the model, stored as numerical values. Some examples of parameters include:
- Weights in neural network layers
- Bias terms
- Embedding vectors for words or tokens
The number of parameters often correlates with the model's capacity to learn and perform complex tasks. However, more parameters also mean increased computational requirements for training and inference.
| Model Size | Parameter Count |
|---|---|
| LLama 3.1 8B | 8.000.000.000 |
| LLama 3.1 70B | 70.000.000.000 |
| LLama 3.1 405B | 405.000.000.000 |
Note: The parameter counts are approximations based on the model names. The actual counts may vary slightly.
Online Chatbots
Online chatbots powered by LLMs have become increasingly popular, offering conversational AI capabilities to users worldwide. Here are some prominent examples:
OpenAI's ChatGPT
- Based on GPT-3.5 and GPT-4 models
- Available through https://chat.openai.com
- Offers free tier with limitations and paid subscriptions (ChatGPT Plus)
- Known for versatile conversational abilities and task completion
- TIP: Microsoft Copilot is based on ChatGPT
Anthropic's Claude
- Available through https://claude.ai and API access
- Emphasizes ethical AI and safety considerations
- Offers both free (with limitations) and paid tiers
Google's Gemini
- Powered by Gemini Flash/pro and other Google AI technologies
- Free Flash version available through https://gemini.google.com/ to use with a Google account
- Pro version only with a subscription
- Integrates with other Google services (e.g., Gmail, Google Drive, Google Sheets, ...) for enhanced functionality
DeepSeek Chat
- Developed by DeepSeek, a Chinese AI company
- Offers both English and Chinese language support
- Free to use with registration at https://www.deepseek.com
These chatbots typically offer:
- Limited free use with restrictions on features or usage quotas
- Paid subscriptions for enhanced capabilities, longer conversations, and priority access
Special Chatbots
Several specialized chatbots have emerged, focusing on specific use cases or offering unique features:
Copilot with Microsoft Edge
- Login with your Education account and click on the Copilot icon in the top right corner
- Copilot, with educational account, uses:
- ChatGPT 4 for chat
- Dalle-3 for image generation
- Prompt:
Explain the content on this page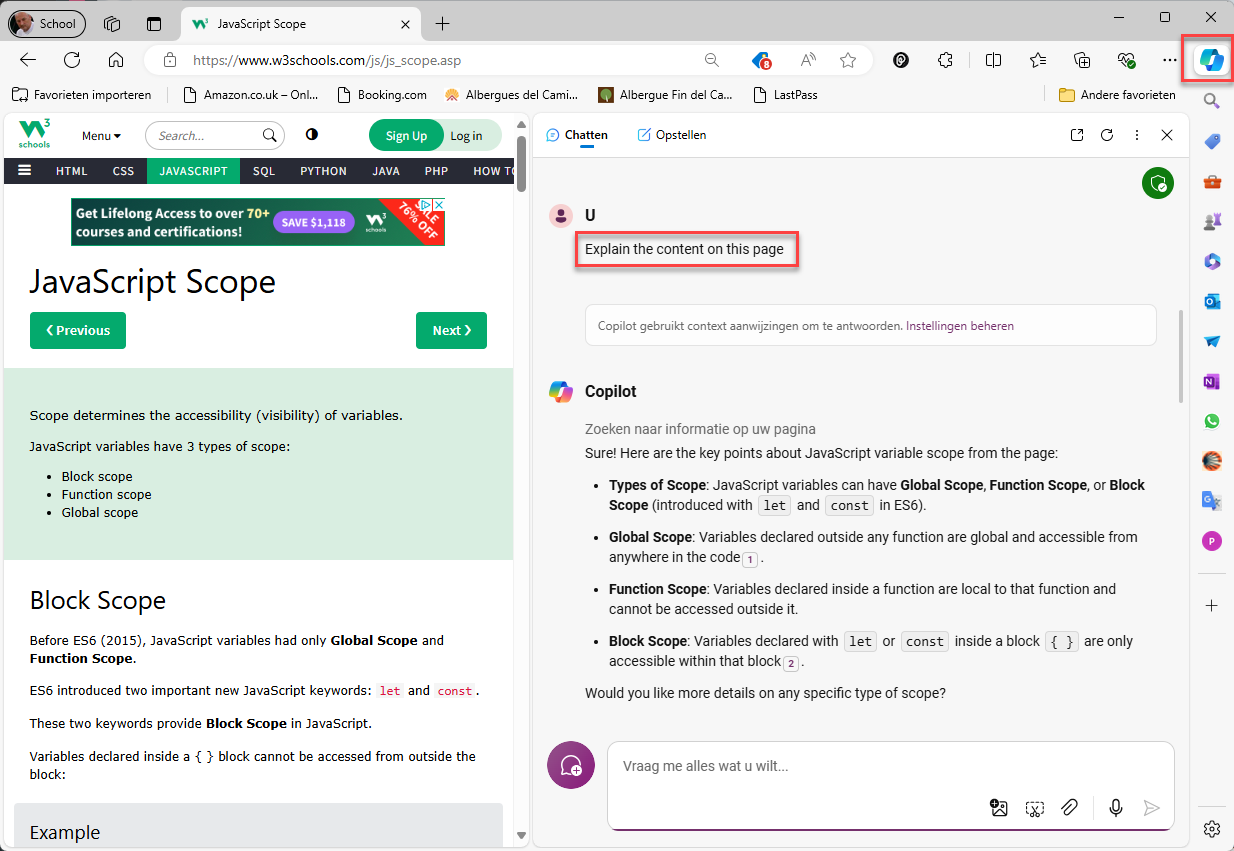
Perplexity AI
- Combines LLM capabilities with real-time web search
- Free tier available through https://www.perplexity.ai
- Focuses on providing up-to-date information and citations
- Shows references to relevant web pages and YouTube videos
- Results depends on the Focus setting (All, Academic, Math, Writing, Video and Social)
- Fee tier has 5 Pro searches per day and 3 PDF uploads per day
- Prompt:
text
For my JavaScript course: create a page about all types of loops.
- Start with a short introduction
- Go over each type of loop and discuss it
- For each loop, provide an exercise for my students to solve
- End with a brief overview showing the differences between the types of loops.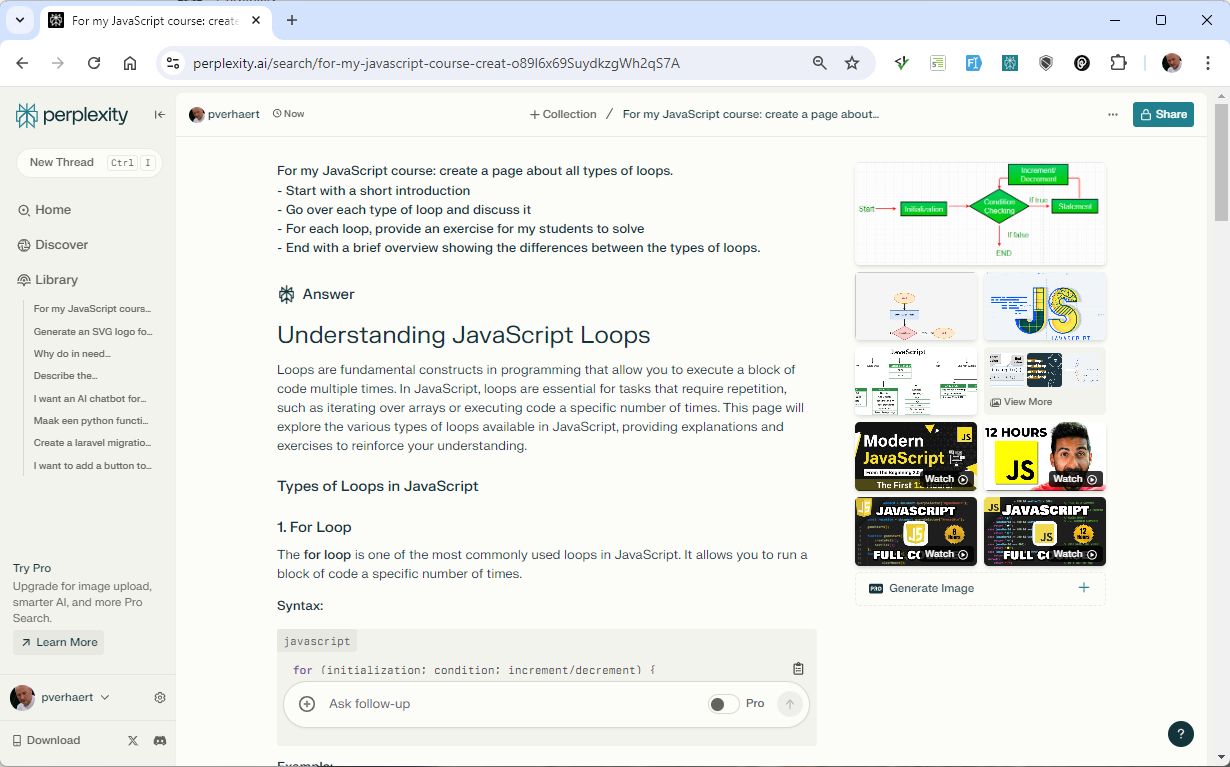
Morphic
- Morphic is totally free for the base model
- Available through https://www.morphic.sh
- It's a alternative for Perplexity
- Prompt:
text
JavaScript: what is the difference between var, let and const.
Explain, give some examples and scribe a short conclusion when to use var, let or const.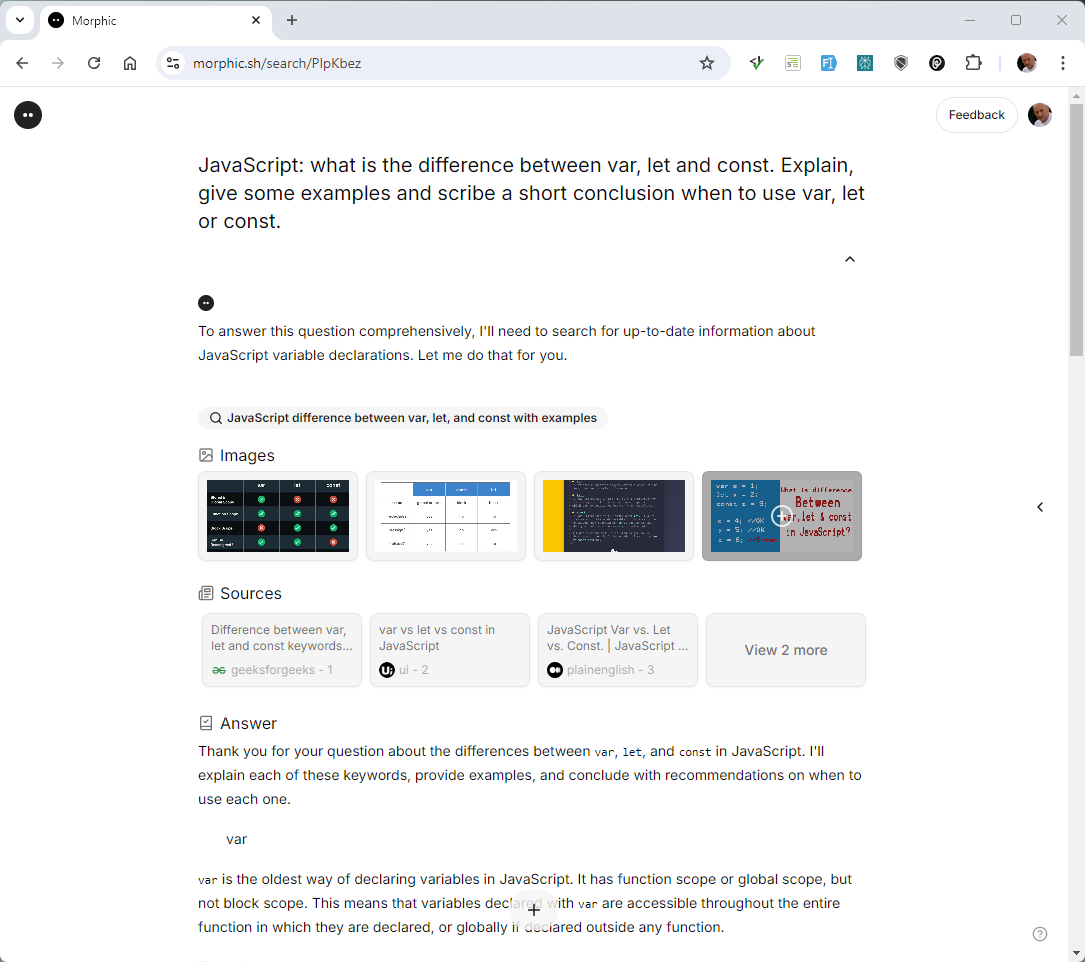
Storm
- Storm creates high-quality Wikipedia-like articles based on a given prompt
- Created by Stanford University: https://github.com/stanford-oval/storm
- You can install Storm on your own server or use it online for free:https://storm.genie.stanford.edu/
- This is an Agent-based tool that uses Claude 3.5 Sonnet to generate the response
(See BrainSTORMing Process for more details about the agents)
- Prompt:
Create an article about the history of NATO - Elaboration:
For educational purposes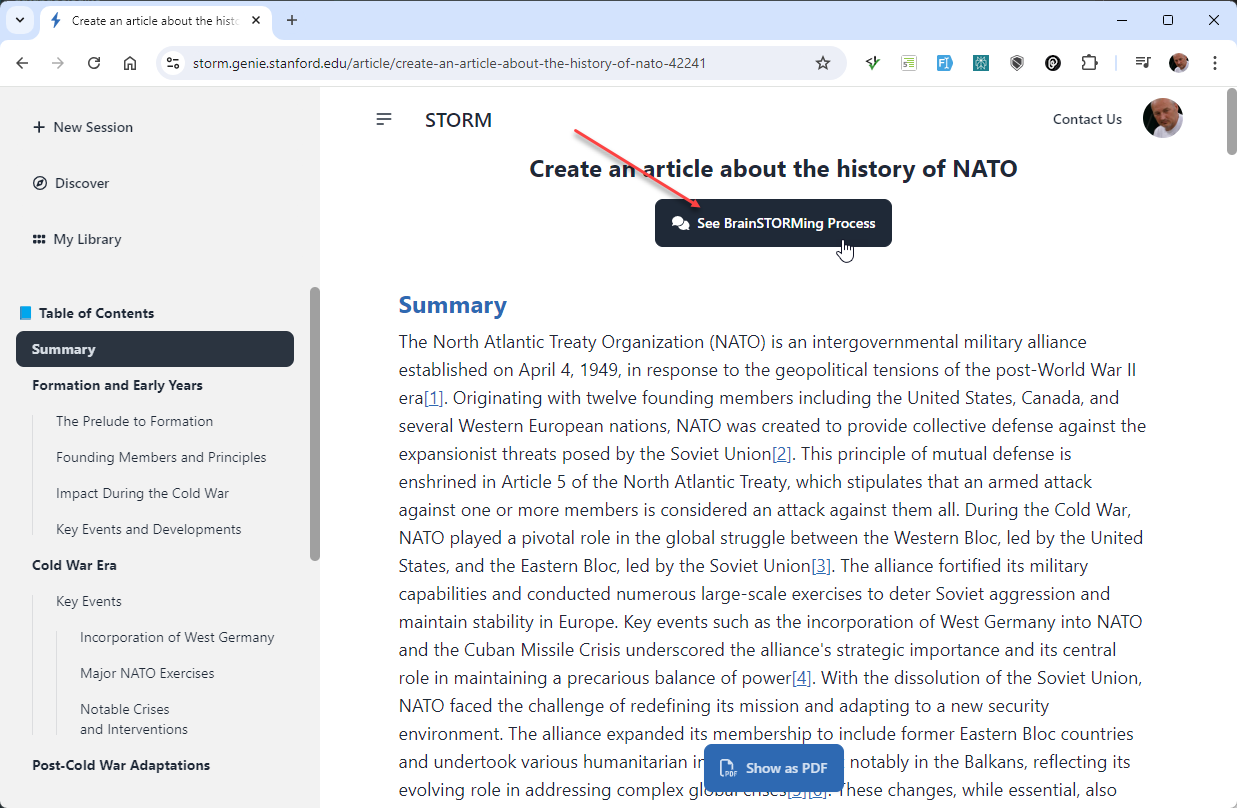
Websim
- Available through https://websim.ai
- At first glance, a nice gadget to make a game with only one prompt
- But it's not very useful for educational purposes...
- Websim als uses the Claude 3.5 Sonnet model and has even better artifacts than Claude!
- Generated code can be downloaded (HTML, CSS and JavaScript)
- Some examples:
- 3D Roller Coaster: `https://websim.ai/@CatKitty19232/3d-roller-coaster-simulator
- SoundFont Keyboard: https://websim.ai/app/soundfont-keyboard
- 3D Torus Viewer: https://websim.ai/c/r2ZbL7pIsv5HEs5H4
- Interactive TV Room With Live Channels: https://websim.ai/c/98NmnjrCmWGnL4aX1
- Try it yourself and look what happens...
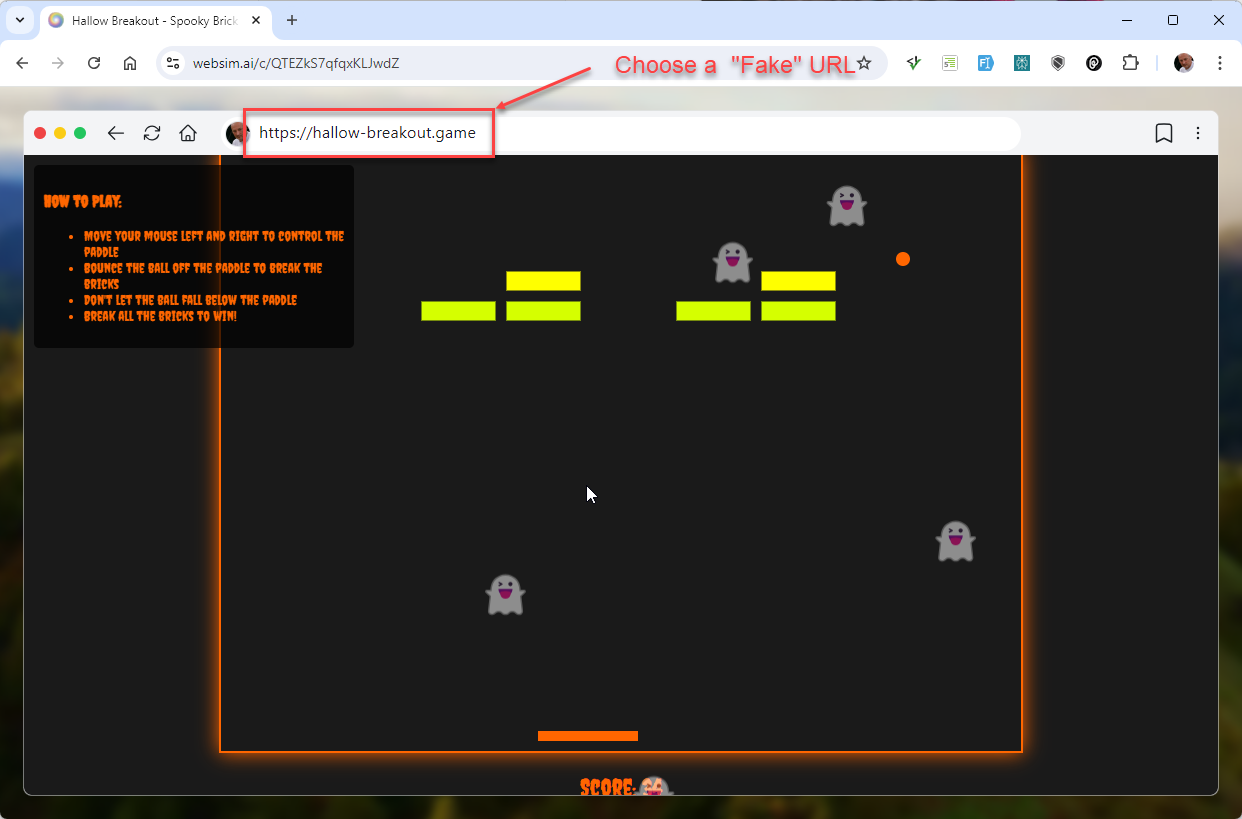
Experiment 1
- Starting with the prompt:
hallow-breakout.game - Re-defining the game with 5 extra prompts
- Result: https://websim.ai/@patrick/hallow-breakout-game
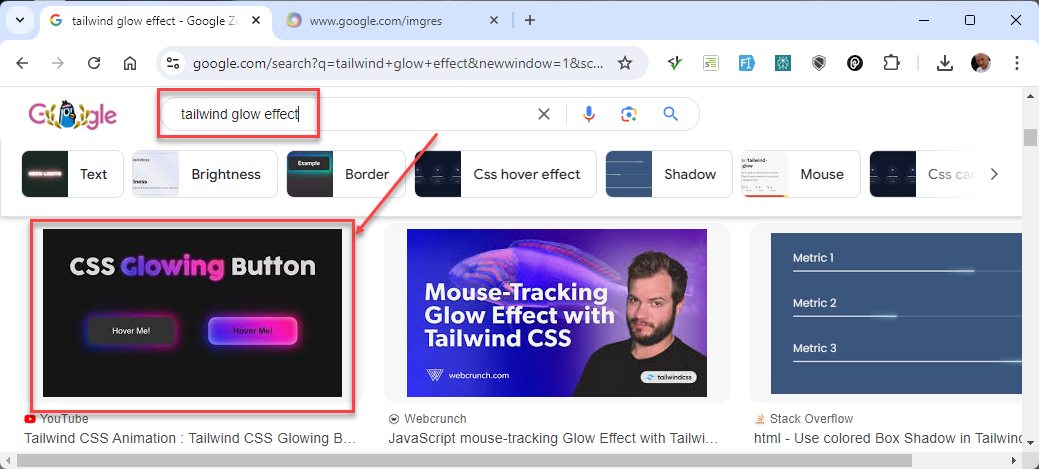
Experiment 2
- Click on the Home icon to start a new project
- Search for
tailwind glow effect - Drag the image you like to use on the URL area of Websim
- Click Enter to start the creation
These specialized chatbots often cater to niche markets or specific professional needs, complementing general-purpose LLM chatbots.
LLM Leaderboard
LLM leaderboards are platforms that compare and rank different language models based on their performance across various tasks. They provide valuable insights into the current state of LLM technology.
LLM leaderboards are:
- Benchmarking platforms for comparing model performance
- Tools for tracking progress in LLM development
- Resources for researchers and practitioners to evaluate models
Popular LLM leaderboards include
- LMSYS Chatbot Arena
- HuggingFace Open LLM Leaderboard
- HELM (Holistic Evaluation of Language Models)
- Vellum LLM Leaderboard
- ...
Common abbreviations and terms in LLM leaderboards:
ARC
AI2 Reasoning Challenge, a question-answering dataset designed to test various reasoning abilities. It includes both easy and challenge sets, covering a wide range of topics and requiring multi-step logical reasoning to solve.BBH
Big Bench Hard, a subset of more challenging tasks from the Big Bench benchmark. This collection focuses on particularly difficult problems that push the limits of language models' capabilities, often requiring advanced reasoning, knowledge application, and problem-solving skills.GPQA
Grade Point Question Answering, a benchmark for question-answering tasks. This dataset typically includes questions that might be found in academic settings, testing the model's ability to understand and respond to complex, multi-faceted queries across various subjects.GSM8K
Grade School Math 8K, a dataset of 8,000 grade school-level math word problems. This benchmark tests a model's ability to understand natural language descriptions of mathematical problems, perform the necessary calculations, and provide step-by-step solutions.Human eval
Human Evaluation, a method to assess AI performance using human judges. This approach involves having human evaluators rate the quality, relevance, and coherence of AI-generated responses, providing a more nuanced assessment of model performance beyond simple metrics.IFEval
Instruction Following Evaluation, a benchmark for assessing how well models follow instructions. This test measures a model's ability to accurately interpret and execute complex, multi-step instructions in various contexts, simulating real-world task completion scenarios.Math
Mathematics benchmark, testing mathematical problem-solving abilities across various difficulty levels and mathematical domains. This can include arithmetic, algebra, geometry, calculus, and more advanced topics, assessing both computational accuracy and problem-solving strategies.MMLU
Massive Multitask Language Understanding, a broad benchmark covering various subjects including science, mathematics, humanities, and more. This comprehensive test evaluates a model's general knowledge and reasoning abilities across a wide range of academic and professional domains.
Benchmarking datasets
Most of these benchmarks are based on predefined datasets. These datasets are carefully curated to ensure they accurately reflect the types of tasks and challenges the models are expected to handle. The datasets are typically standardized to allow for consistent and fair comparisons across different models and over time.
However, it's important to note that while the core datasets may remain relatively stable to ensure continuity in evaluations, they can also evolve and be updated over time.
LLM Comparison
Comparing LLMs across different applications helps users and developers choose the most suitable model for their needs. Here's a brief comparison for chat and programming applications:
Chat Comparison
| Model | Conversational Ability | Contextual Understanding | Multilingual Support | Multimodal Capabilities |
|---|---|---|---|---|
| GPT-4o | Excellent | Exceptional | Extensive | Advanced |
| Claude 3.5 | Excellent | Very High | Strong | Advanced |
| Gemini 1.5 | Excellent | Very High | Strong | Advanced |
| Llama 3.1 | Very Good | High | Strong | Limited |
| Mistral Large | Very Good | High | Strong | Limited |
Programming Comparison
| Model | Code Generation | Debugging | Documentation | Multi-language Support | AI-assisted Development |
|---|---|---|---|---|---|
| GPT-4o | Exceptional | Excellent | Excellent | Extensive | Advanced |
| Claude 3.5 | Excellent | Very Good | Excellent | Strong | Advanced |
| Gemini 1.5 | Excellent | Very Good | Very Good | Strong | Advanced |
| CodeLlama 2 | Excellent | Excellent | Very Good | Extensive | Very Good |
| GitHub Copilot | Very Good | Very Good | Very Good | Strong | Excellent |
These comparisons are based on the latest available information as of August 2024. However, it's crucial to note that:
The field of LLMs is rapidly evolving, and new models or updates can change these rankings quickly.
Performance can vary significantly based on specific tasks, contexts, and how the models are fine-tuned or implemented.
Many of these models receive regular updates, which can improve their capabilities over time.
Actual performance may vary in real-world applications, and users should conduct their own evaluations for specific use cases.
Some models, like GPT-4o and Gemini 1.5, are relatively new and their full capabilities are still being explored by the community.
OpenAI's Path to AGI
OpenAI has outlined a 5-step plan for achieving Artificial General Intelligence (AGI).
As of 2024, we are transitioning from Level 1 to Level 2.
Read more: https://www.tomsguide.com/ai/chatgpt/openai-has-5-steps-to-agi-and-were-only-a-third-of-the-way-there

Level 1. Chatbots (Current Level)
- AI with natural conversational abilities
- Examples: GPT-3.5, GPT-4o, Gemini Pro 1.5, Claude Sonnet 3.5
- Capabilities: Complex conversations, some memory, limited reasoning
Level 2. Reasoners (Emerging)
- Human-level problem-solving across broad topics
- Frontier models approaching this level
- Expected in upcoming models like GPT-4.5?, Strawberry?, Orion? , Claude Opus 3.5?
Level 3. Agents (In Development)
- Independent action-taking AI systems
- Content creation without direct human input
- Some companies building agentic systems
Level 4. Innovators (Future Goal)
- AI aiding in invention and expanding human knowledge
- Creation of novel ideas and solutions
- Initial steps: OpenAI's partnership with Los Alamos National Laboratory
Level 5. Organizations (Final AGI Stage)
- AI capable of running entire organizations independently
- Requires broad intelligence and systemic understanding
- Not yet achieved
While rapid progress is being made, the path to AGI involves overcoming significant technical and ethical challenges. The timeline remains uncertain, and ongoing discussions about responsible AI development are crucial.
Abacus: ChatLLM
Abacus ChatLLM is a versatile platform that offers a range of capabilities for working with large language models. Here are some of its key features and possibilities:
Access to Multiple LLMs:
ChatLLM provides access to a wide range of state-of-the-art language models, including GPT-4o, GPT-4o mini, Claude Sonnet-3.5, Gemini 1.5 Pro, LLama 3.1 405B, and Abacus SmaugSearch LLM:
Search LLM is a Perplaxity clone with references to links to relevant resources, images, videos and news articles.Web Search Integration:
Users can perform web searches directly through the ChatLLM interface, enhancing the AI's ability to provide up-to-date information.Image interpretation
Just like e.g. GPT-4o, ChatLLM can interpret images and provide insights into their content and you can chat with it.Image Generation:
The platform includes capabilities for AI-powered image generation, expanding its utility beyond text-based interactions. Images are creating with DALL-E and Flux 1 ProCode Execution:
ChatLLM can write, execute, and analyze code, making it a powerful tool for developers and data scientists.
It also has "artefacts" like the Anthropic chatbot Claude 3.5 Sonnet and Genini 1.5 ProDocument Interaction:
Users can chat with PDFs and other document types, facilitating easy information extraction and analysis from various sources.Custom Chatbot Creation:
The platform allows for the development of customized chatbots tailored to specific needs or knowledge bases.
Pricing $10/month
- ChatLLM Teams is priced at only $10 per user per month for unlimited access to all those frontier models.
Indivividual pricing:- ChatGPT Plus: $20 per month
- Anthropic: $20 per month
- Google Gemini Advanced: €21.99 per month
- The first month is offered free of charge.
- A minimum subscription of 2 months is required.
- Please follow this link if you want to try it out for 2 months.
(Then I get a small reduction on my next payment 😉 )
- Prompt:
text
Create a javascript function that gets the real-time information about the Belgium railway.
Show a dashboard page wit the actual information about the trains departing from Geel.
You can use the internet to search for actual information about the API.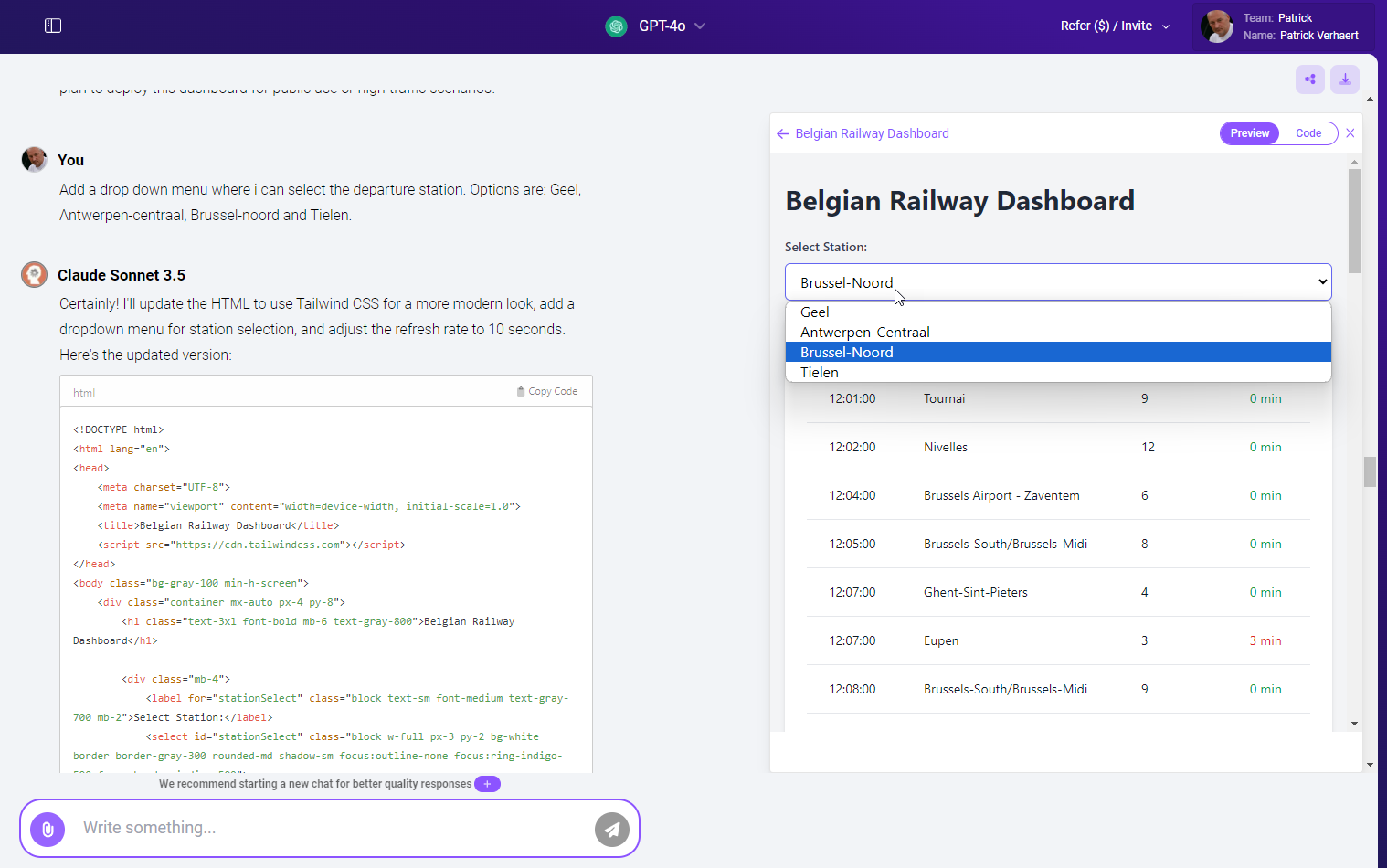
The making of ...
Almost the entire page is built with ChatLLM and the Claude Sonnet 3.5 model. Here are the steps in the process:
- Step 1: create an outline fot this page
- Step 2: write a basic system prompt on how the page should look like
- Step 3: write the subtitles for each part of the page
- Step 4: let the LLM optimize your basic system prompt and the subtitles
- Step 5: use the LLM to write the content for each part of the page
- Step 6: ask the LLM to create some images that illustrate the content
URL: https://apps.abacus.ai/chatllm/57832bef0/?convoId=6486a2bce
- Prompt:
text
You are a specialist in course development and write detailed texts in concise but easily understandable language for non-specialists.
Write a detailed chapter on Large Language models using the structure provided. Add additional topics if you think they are important to the topic.
Search the Internet for recent sources first.
For references to websites, always put the link on the title.
Display the result in a markdown code block!
Make sure the markdown contains no syntax errors.